After spending some time on a system to make names for places as described in my last project post I thought it would be interesting to look at creating countries for my planet I could then attach such names to. I wanted to create a system where I could determine from any point on the surface of the planet which country it was part of.
I thought the easiest way to go about this would be to create a triangulated shell around the planet against which a ray from and normal to the surface could be intersected, the triangle that was hit would let me know which country the point was within.
My very first go at this involved setting up an array of 200 points chosen at random around the surface of a sphere enclosing the planet, these were created by simply choosing random numbers in the [-1, 1] range for the X, Y and Z positions then normalising the resulting vector. Once I had these I use the
QuickHull Algorithm to produce a triangulation of the convex hull formed by these points and assigned a country ID to each - albeit really just a colour at this point. The control net mesh looked like this:
 |
| Triangulation of country control net created purely from seed points |
For now I'm just using a sphere created by subdividing an Icosahedron for my planet's terrain and it's purely spherical with no elevation variation to ease visualisation. Taking the centroid of each terrain triangle and shooting a ray from it normal to the surface against the country boundary control net described above then colouring the terrain triangle with the country ID proves the concept of determining countries from surface points:
 |
| Countries found by ray-casting from the surface |
Note the jagged edges of the triangles here (shown in close up in the top corner) in contrast to the smooth ones in the direct rendering of the control net above - remember this second image shows the individual terrain triangles flat shaded, effectively point sampling the country control net.
Unless you know of a planet with purely triangular countries though it's not particularly realistic. To make the results a bit more organic I played with adding some noise to the vector shot from the surface against the control net which initially produced some slightly more encouraging results:
 |
| Perturbing the ray from the surface |
The triangular nature of the control net however is still quite apparent and more problematically closer examination reveals there are problem cases where the noise causes unrealistic "bubbles" of a country to leak into adjacent countries due to the perturbation of the vectors being intersected against the control net. This occurs most near the country boundaries as points on one side can end up being displaced enough to end up embedded in the neighbouring country:
 |
| "Bubbles" of one country leaking into it's neighbour |
This is not something you generally see in the real world and was what I felt to be an unacceptable results which unfortunately I couldn't think of a way to correct. I ruled out noise perturbation as a result and went back to the drawing board.
Edge Subdivision
Instead of noise then I had to come up with plan B - my second approach was to subdivide the edges of the triangles adding displacements to the introduced points to make the edges more interesting. In this way the boundaries can be more interesting while still preventing "bubble" errors. The process here is to recursively divide any boundary edge over some minimum length introducing a new boundary point in the middle of it. The cross product of the edge vector and the normal gives a tangent which is used to displace this new point by some random amount. The magnitude of this displacement is capped to be a proportion of the length of the edge so long edges have their midpoint displaced further than short edges to keep things in proportion.
Subdividing the edges did turn my nice triangles into n-gons so I also had to add in a triangulation step to turn each set of country boundary points back into a mesh I could both ray test against and render for debugging purposes. As I knew the boundaries couldn't have holes I used the trusty
Ear Clipping Algorithm as it's so simple to implement and fast enough for this case.
There is still a potential for error here though as there is a possibility that the displaced midpoint might end up within an adjacent country's boundary causing the boundary edges to intersect creating invalid boundary pockets:
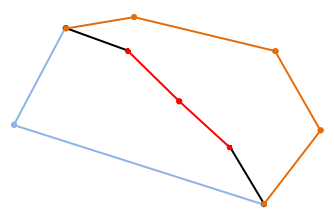 |
| An edge between two countries that has been subdivided |
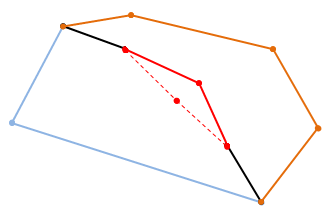 |
| Displacing the newly introduced midpoint perpendicularly to the edge by a distance proportional to the edge's length to make the boundary more interesting... |
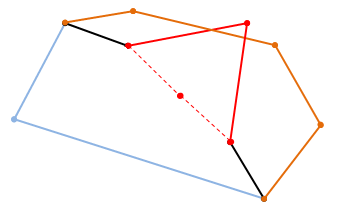 |
| ...but if you displace it too far the new edges can intersect the other existing edges of one or other boundary making an invalid boundary |
So for each potentially displaced midpoint the two edges that would connect it to the original edge's end points are tested for intersecting any of the remaining edges of the two boundaries that adjoin across the edge being split.
If no intersection is found the displaced point is valid and I move on testing the two created edges to see if they in turn can be sub-divided, if however either of the two new edges intersect a remaining edge I have to pick a new position for the midpoint and try again. To reduce the chance of getting stuck trying to find a valid position each time I have to reposition it I reduce the maximum magnitude of the displacement with each attempt so the new midpoint gradually tends back to the original edge. If the magnitude gets so low it's not worth dividing the edge at all I just give up, leave the original edge undivided and move on to the next edge. This only tends to happen in highly acute boundary corners where slivers are produced.
Running the process dividing any edge longer than 50Km gives a noticeably better result than the simple triangles I started with:
 |
| Country control net produced by subdividing edges of triangular countries |
Although it's better there is no getting away from the fact that I started with triangles and I was still not particularly happy with it. To make the country shapes more interesting my next step was to randomly take pairs of adjoining countries and merge them together producing fewer hopefully more interesting shapes:
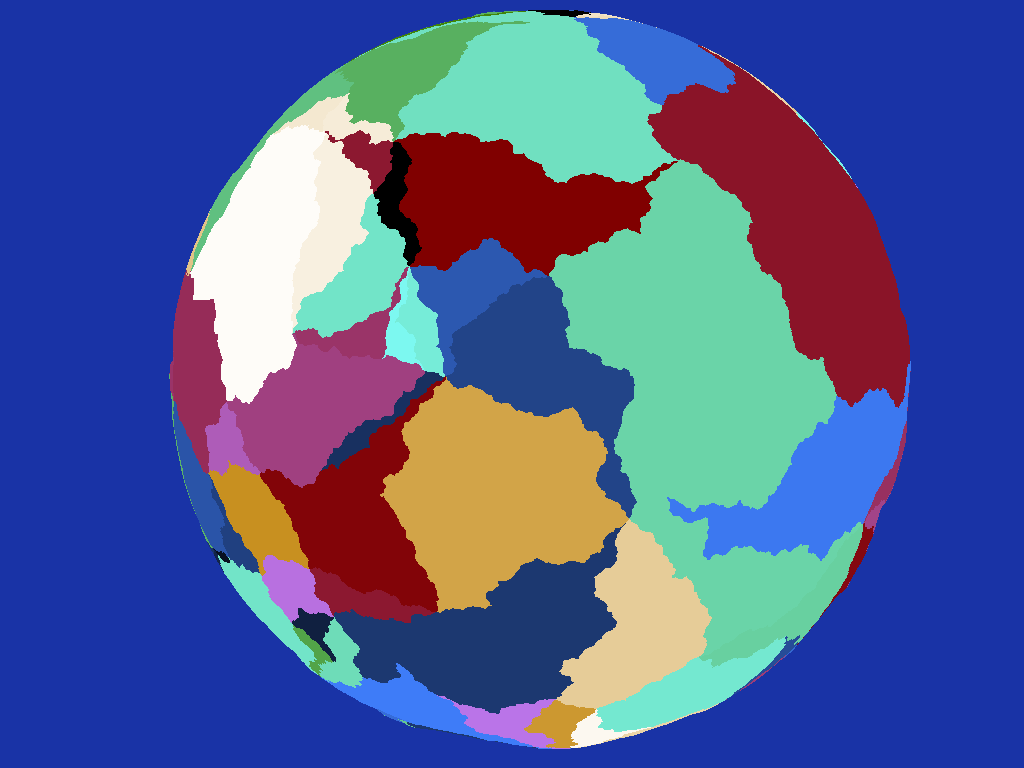 |
| Randomly merging adjacent countries helps obscure their triangular origins somewhat |
Another improvement but again to me it's still quite obvious I started with triangles - there are a large number of nexus points where to my mind an unrealistically high number of countries meet at a single place:
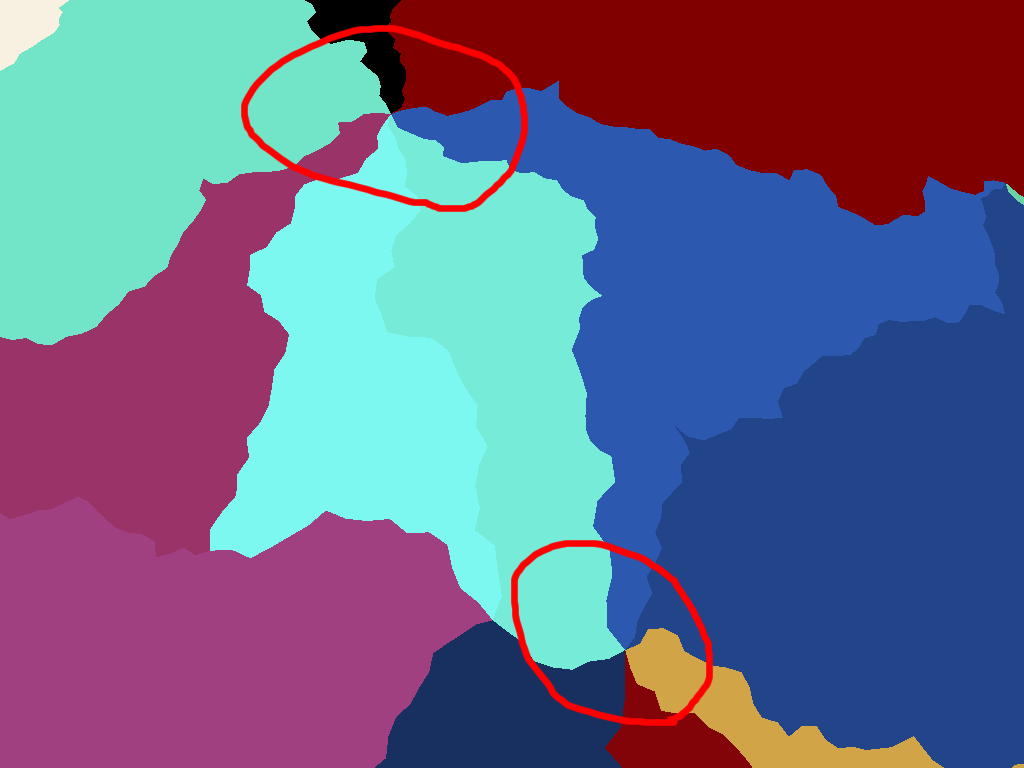 |
| Unrealistic nexus points where many countries meet, another consequence of the triangular basis |
I experimented with increasing the number of seed points which meant more smaller triangles to start with but although the effect was improved a bit more it felt more like treating the symptom than a cure.
Dual Meshing
Rather than shrink the triangles I thought it would be better to start from a more friendly base so instead of using the triangulation of the convex hull surrounding my initial seed points I instead calculated the
dual of this mesh effectively producing faces surrounding each seed point rather than passing through them. This immediately gave me what I thought was a better initial mesh, effectively similar to a 3D Voronoi diagram:
 |
| Using the dual of the triangular mesh produces better country shapes as a basis |
Running the edge subdivision on this mesh finally gave me a result I was pretty happy with:
 |
| Subdividing the edges of the new countries makes them more realistic |
I also added back the random merging of adjacent countries to make things more varied:
 |
| Randomly merging adjacent countries provides more variety of scale |
Note how the irritating nexus points no longer feature, the countries join in what I feel to be a far more realistic manner. The main issue I have with it now though is the countries before merging are a bit too similar in size causing the result to be a bit uniform - I think in the future I'll play around with clustering the seed points somehow instead of having them uniformly random and see how that affects things.
Note the triangulation of the country boundary control net doesn't necessarily produce a spherical mesh as such as the edges of triangles spanning large areas will at times be much closer to the centre of the sphere than their unit length vertices producing odd looking kinks in the geometry:
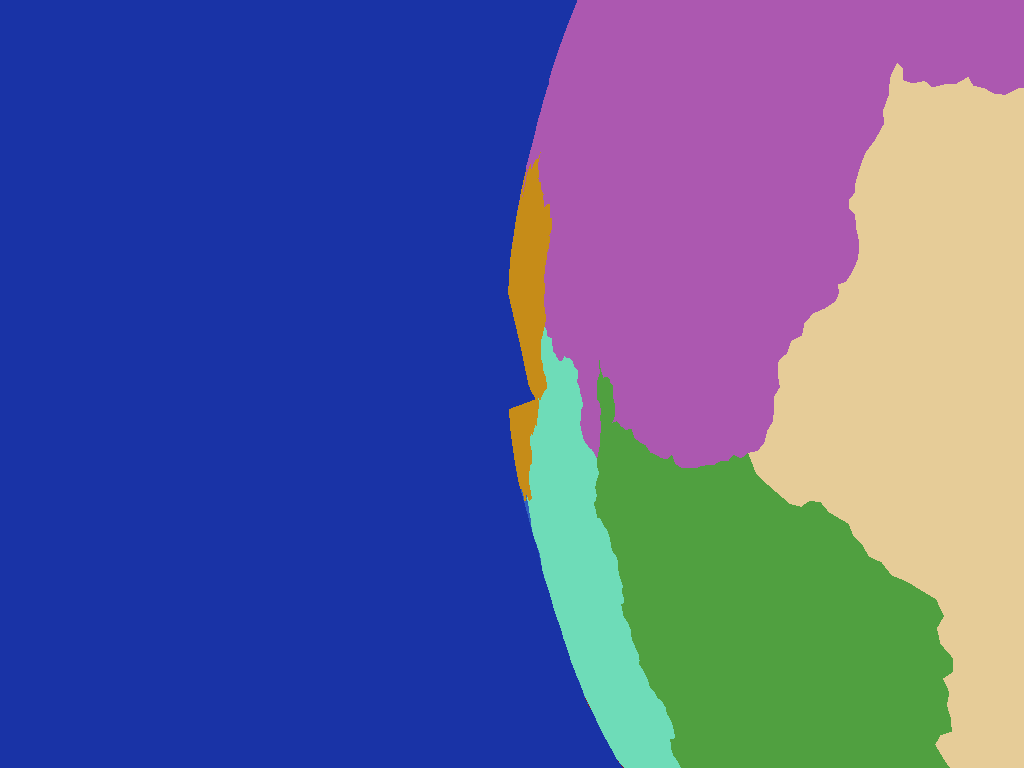 |
| An obvious kink in the yellow country caused by the control net's triangles spanning a wide solid angle on the planet |
this isn't a problem however as remember I'm not normally rendering the country boundary geometry directly, I'm just intersecting rays shot from the far denser planet surface mesh against it to determine which country a point is located within.
A Note on Ray-Triangle Intersections
While working on this there were a number of times when I had to intersect rays or 3D line segments with triangles. I was using a trusty old intersection routine I've had kicking around for years but found that even with double precision there were times when a ray or line would be reported as missing a triangle that it really should have intersected, usually when falling on an edge between two adjoining triangles. Puzzled by this I did a little research (i.e. consulted Google) and found a better intersection algorithm specifically designed for intersecting with meshes, "
Watertight Ray/Triangle Intersection"
Implementing this solved all my problem cases in one fell swoop so it turned out to be a good find, if you are interested in using it do note however that there appears to be a minor error in the code presented in the paper, see near the bottom of
this blog post for more info.
Conclusion
Although this has been focussed on country generation, while working on it I have thought that the system could also be used to produce areas of water for oceans and seas by simply flagging certain boundaries as water zones. This would produce some nicely shaped features while avoiding the problem of parts of a country being underwater if water was placed by a different system. I will need to feed the country boundaries into the elevation production system however for this to work so the water zones and coastlines are given appropriate topology. Something for the future anyway.
So there you have it, a set of what I feel are quite realistically shaped countries I can use to move on to the next step, possibly placement of towns and cities followed by primary road or rail networks...that sounds like it should be interesting to look into anyway.




